TF-IDF에 대하여
TF-IDF 란?

TF-IDF(Term Frequency-Inverse Document Frequency)는 정보 검색이나 텍스트 마이닝 (Text Mining) 에서 기본적이고도 핵심적인 알고리즘입니다.
TF-IDF는 단어의 상대적인 중요도를 평가하는 데 사용되며, 특정 단어가 문서 내에서 얼마나 중요한지를 평가하는 데 사용됩니다.
이는 단어의 빈도와 역 문서 빈도를 곱한 값으로 계산되죠.
TF-IDF의 구성 요소
TF-IDF는 두 가지 주요 구성 요소로 이루어져 있습니다:
TF (Term Frequency)
TF(Term Frequency)는 특정 단어가 문서 내에서 얼마나 자주 등장하는지를 측정합니다.
TF는 단어 빈도를 문서 내 전체 단어 수로 나누어 계산됩니다.
$ \text{TF}(t, d) = \frac{\text{해당 단어의 빈도 (t)}}{\text{문서의 전체 단어 수 (d)}} $
IDF (Inverse Document Frequency)
IDF(Inverse Document Frequency)는 특정 단어가 전체 문서 집합에서 얼마나 드물게 등장하는지를 나타냅니다.
자주 등장하는 단어의 가중치를 낮추고, 드물게 등장하는 단어의 가중치를 높이는 역할을 합니다.
$ \text{IDF}(t, D) = \log \left(\frac{N}{\text{df}(t)} + 1\right) $
예시
다음은 TF-IDF를 계산하는 간단한 예시입니다.
우리에게 총 4개의 문서가 있다고 생각해보겠습니다.
- “고양이 키우는 방법”
- “강아지 고양이 차이점”
- “강아지 훈련법”
- “고양이 강아지 식습관”
이제 위 문서들에서 우린 “고양이“라는 단어의 TF-IDF 값을 계산해보겠습니다.

위 표에서 볼 수 있듯이, “고양이“라는 단어는 문서 1, 2, 4에서 등장하고 있습니다.
1, 2, 4번 문서의 TF값은 0.333 으로 모두 동일하게 나오며, “고양이” IDF는 0.367 이 나옵니다.
최종적으로 TF-IDF 값은 0.122 가 나오게 되고
우리가 “고양이“를 검색했을 때, 문서 1, 2, 4가 가장 관련성이 높다는 것을 알 수 있습니다.

그렇다면 강아지도 같은 방식으로 계산해보면 어떨까요?
“강아지“라는 단어는 문서 2, 3, 4에서 등장하고 있습니다.
문서 3을 보면 TF 값이 0.5로 가장 높게 나오며, 2번과 4번 문서의 TF 값은 0.333으로 동일하게 나옵니다.
“강아지의” IDF 값은 고양이와 동일하게 0.367 이 나오게 되고,
3번 문서가 다른 문서와 비교했을 때 가장 높은 TF-IDF 값을 가지게 되는 걸 볼 수 있습니다.
2번과 4번 문서는 단어가 3개인 반면, 3번 문서는 단어가 2개밖에 없기 때문에 관련성이 더 높다고 판단하는 것이죠.
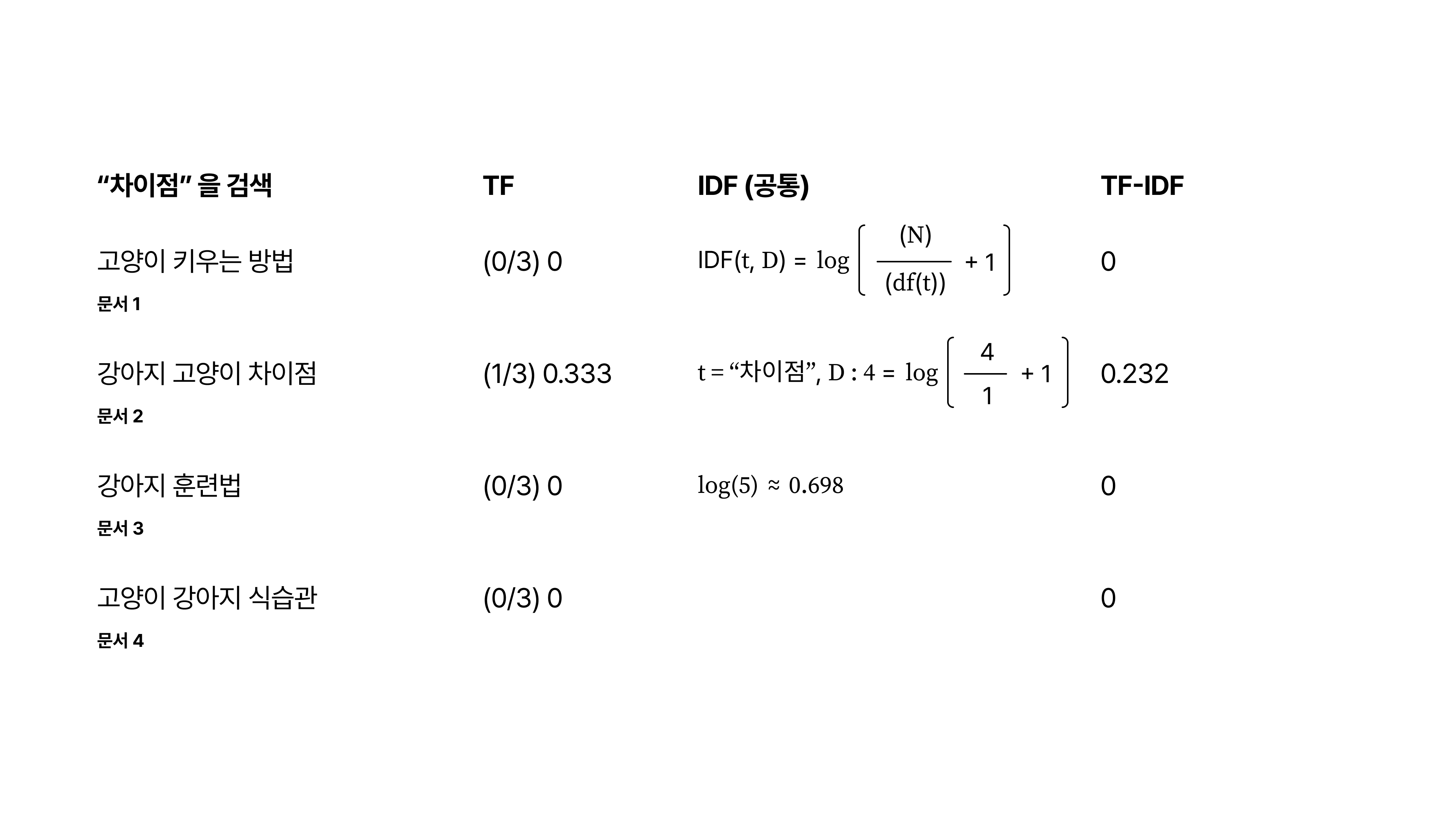
마지막으로 “차이점“이라는 단어를 살펴보겠습니다.
우선 “차이점“이라는 단어는 2번 문서에서만 등장하고 있습니다.
계산된 TF-IDF를 보면 0.232 이고, 위의 TF-IDF 값과 비교했을 때 보다 더 높은 점수인 것을 볼 수 있습니다.
“차이점” 이라는 단어가 문서 내 유일하게, 그리고 매우 드물게 등장하고 있기 때문에 IDF 값이 높게 나오게 되고 TF-IDF 값이 높게 나오는 것이죠.
결론
이처럼 TF-IDF는 단어의 상대적인 중요도를 평가하는 데 사용되며, 특정 단어가 문서 내에서 얼마나 중요한지를 평가하는 데 사용됩니다.