[PostgreSQL] 검색을 위한 GIN Index 소개
GIN Index란?
GIN(GENERALIZED INVERTED INDEX) 처리할 쿼리가 복합적인 데이터인 경우에 사용하면 좋은 성능을 보여주는 인덱스입니다. 복합적인 데이터는 예를 들어 배열, JSON, hstore, tsvector 등이 있습니다.
그리고 해당 포스트에서는 검색을 위한 GIN Index에 대해 알아보겠습니다.
우리가 찾을 값이 문서(Document)라고 가정하면, 특정 단어를 포함하는 문서를 더 빠르게 찾기 위해 GIN Index를 사용할 수 있습니다.
- Item: 인덱싱할 값 - 문서
- Key: 요소 값 - 단어
GIN은 항상 키를 저장하고, 검색하며 아이템 값 자체를 검색하는 것은 아닙니다. 그렇단 말은 GIN Index는 아이템 값이 아닌 키를 저장하고, 키를 검색하여 아이템 값을 찾는 방식입니다.
GIN Index 핵심 개념
- (key, posting list) 쌍의 집합을 저장합니다.
- key는 인덱싱할 값이며,
- posting list는 해당 key를 가진 아이템의 리스트입니다.
- 하나의 Row ID는 여러 개의 posting list에 속할 수 있습니다. (하나의 아이템이 여러 개의 key를 가질 수 있음)
- 같은 키 값은 한 번만 저장되므로, 동일한 키가 여러 번 나타나는 경우에 GIN 인덱스는 압축을 수행하고 매우 효율적으로 저장할 수 있습니다.
이해가 어려워서 간단하게 이미지로 GIN Index의 핵심 개념을 설명해보겠습니다.
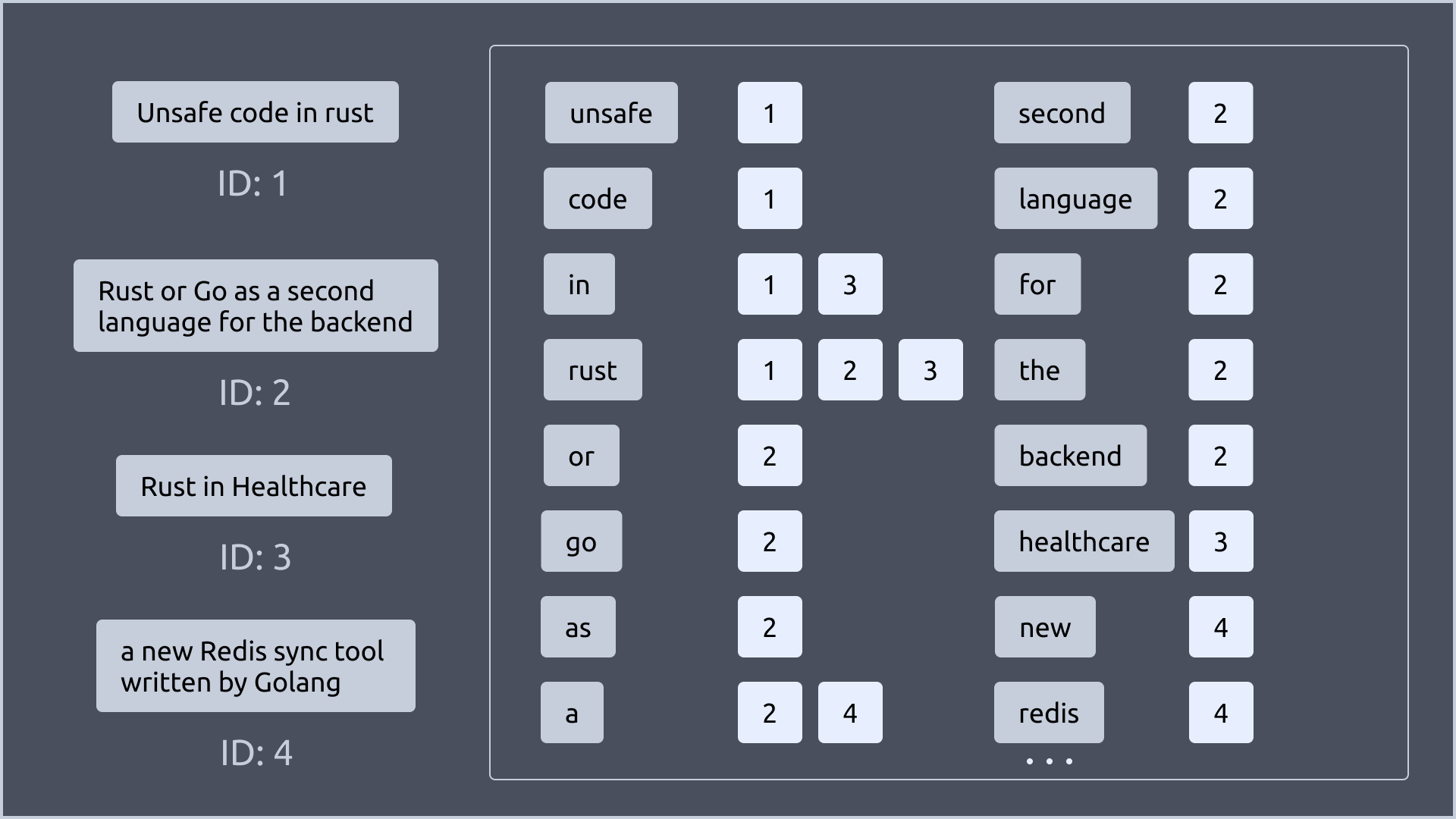
우선 4개의 문서가 있다고 가정해보겠습니다.

그리고 각 문서들을 단어로 나누어보겠습니다. 한가지 추가적으로 처리한 것은, 대문자를 소문자로 변환했습니다.
여기서 단어는 위에서 말한 key가 됩니다.
그림에서 보이는 것 처럼 각 key 뒤에는 번호가 붙어있습니다. 이 번호는 해당 key를 가진 문서의 ID라고 이해하면 됩니다.
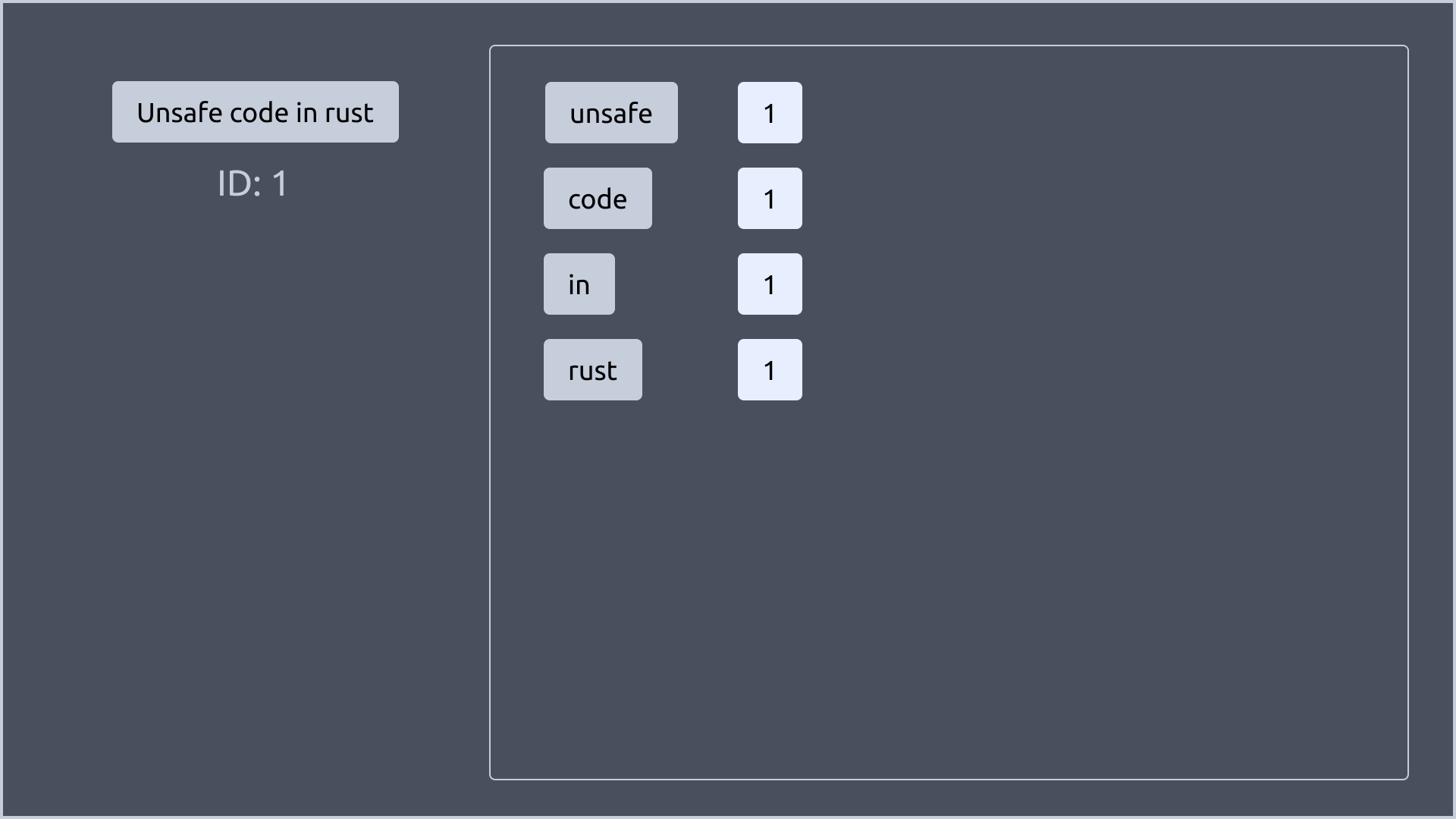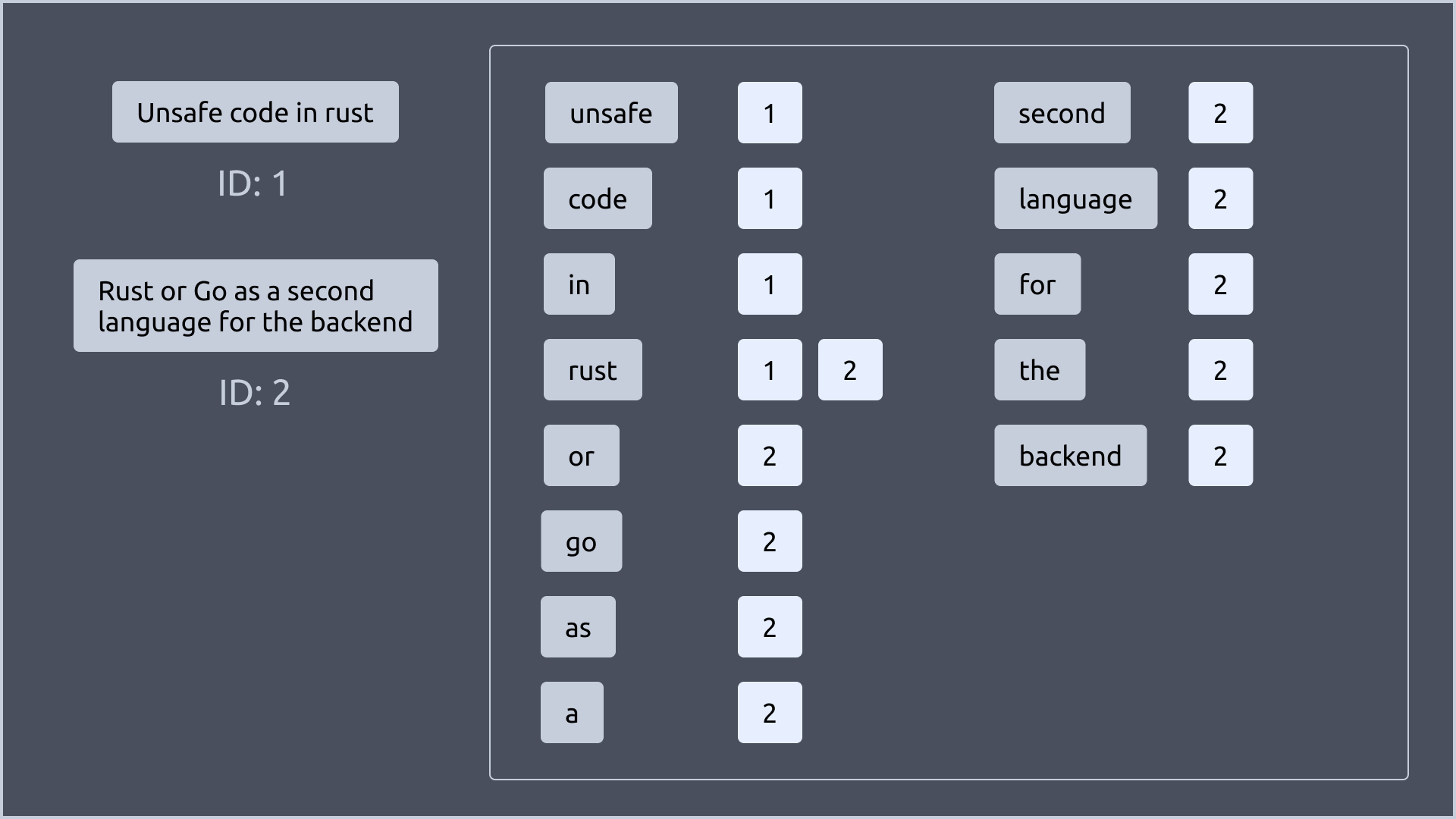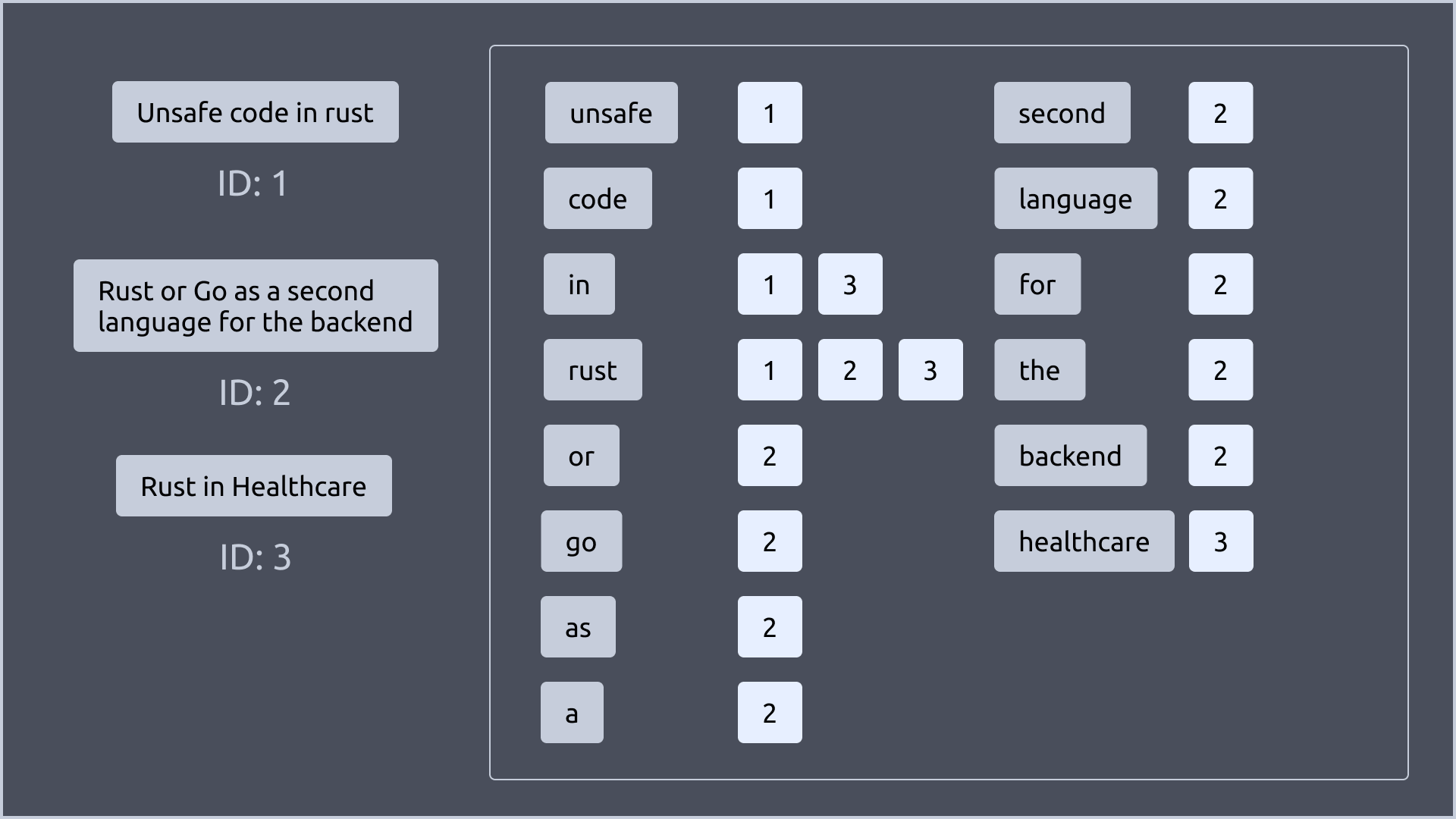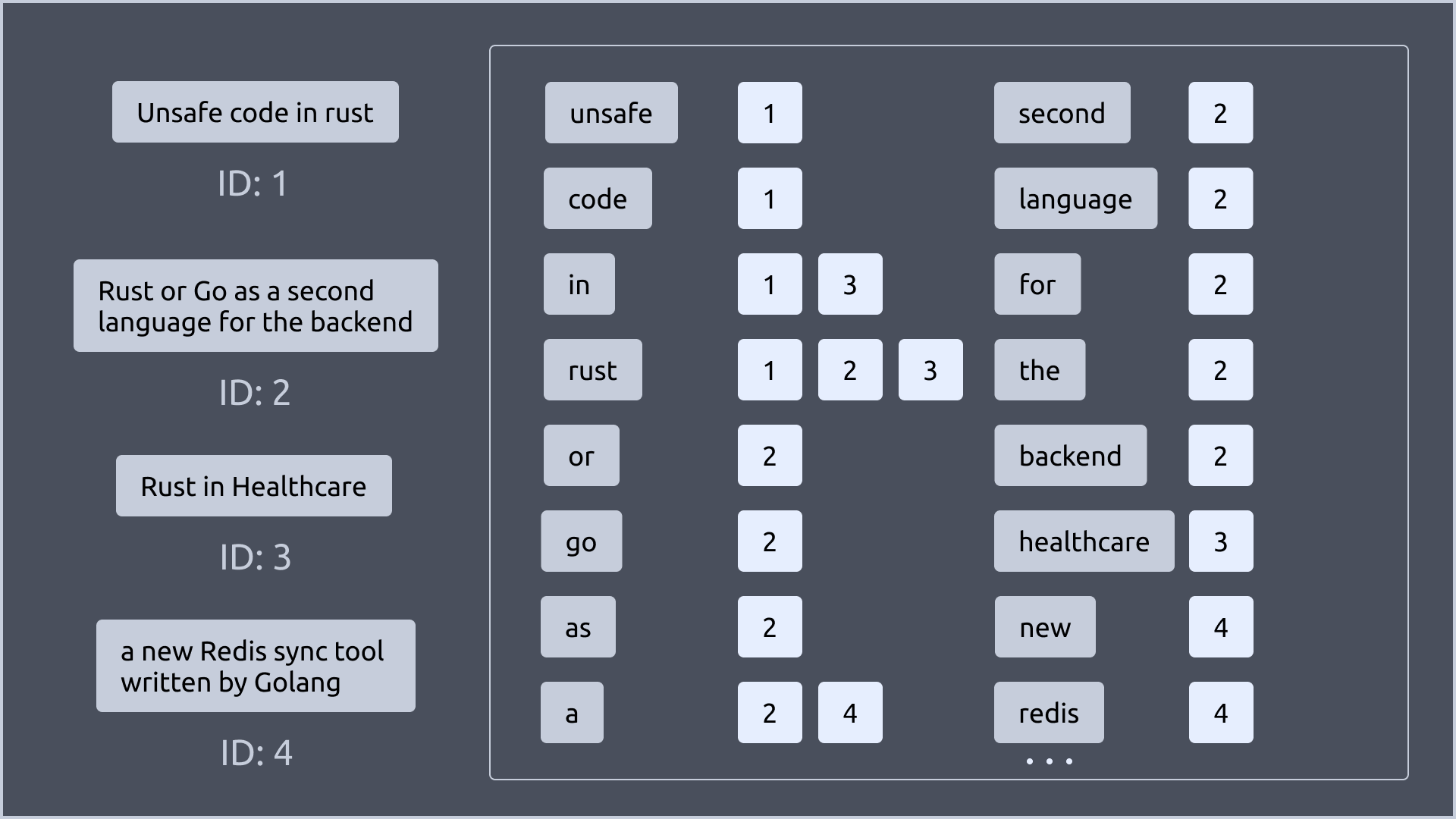
최종적으로 GIN Index는 다음과 같이 구성됩니다.
이제 GIN Index를 사용하여 검색을 수행해보겠습니다.
예를 들어, “rust“라는 단어를 포함하는 문서를 찾고 싶다면, GIN Index를 사용하여 “rust“라는 key를 찾고, 해당 key를 가진 문서의 ID를 찾으면 됩니다.
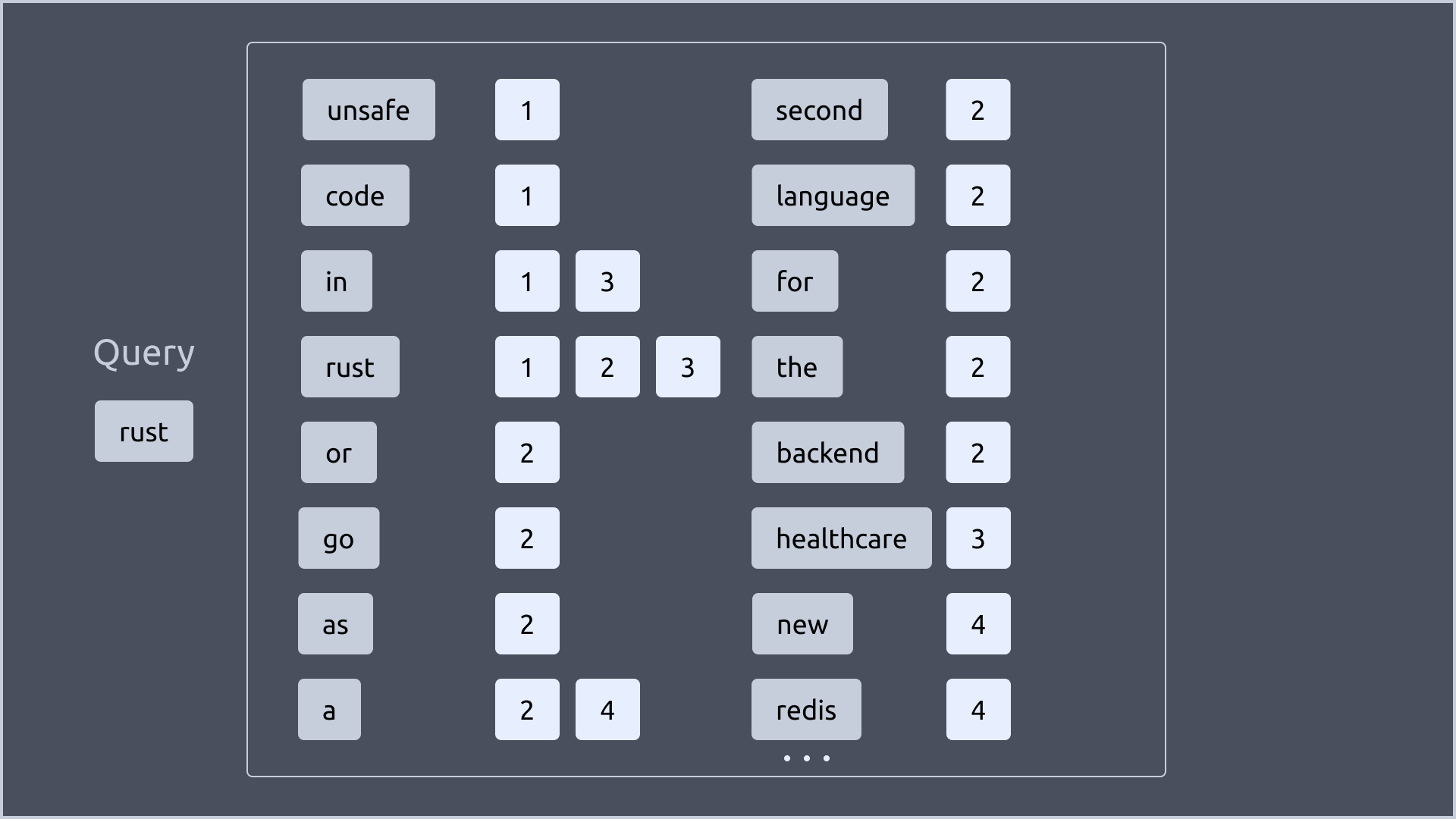
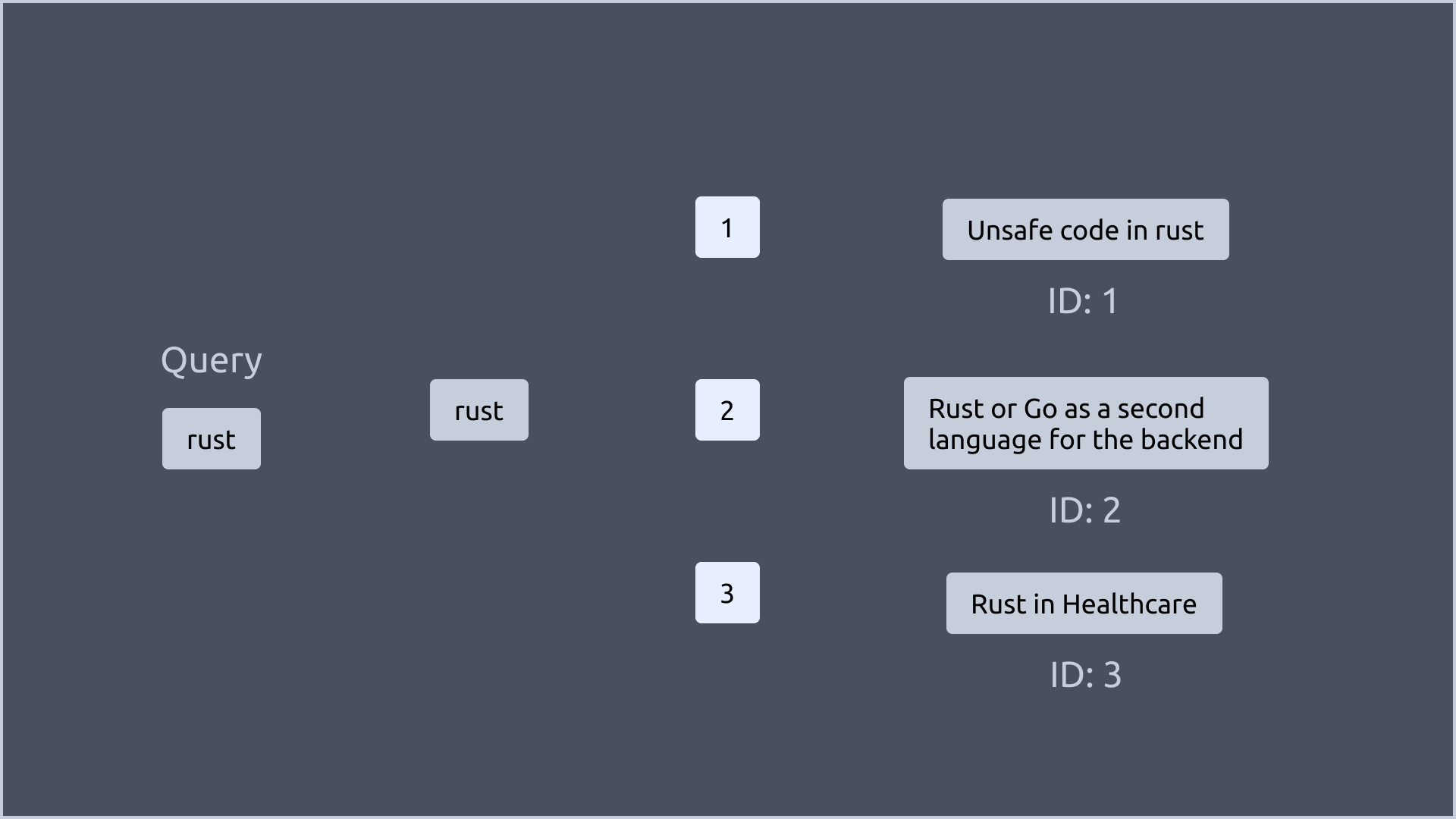
아래 그림에서 보이는 것처럼 “rust“라는 key를 가진 문서는 1, 2, 3번 문서입니다.
이렇게 “rust” 라는 단어를 포함하는 문서를 찾는데 모든 문서를 스캔하지 않고, GIN Index를 사용하여 빠르게 찾을 수 있었습니다.
GIN Index가 잘하는 일
- DBA같은 데이터베이스 전문가가 아닌 사람도 쉽게 사용할 수 있습니다.
- 복합적인 데이터를 처리할 때 빠른 검색 속도를 제공합니다.
- 특정 단어를 포함하는 문서를 빠르게 찾을 수 있습니다.
- auto-vacuum 기능을 지원해서 인덱스를 자동으로 관리하고 최적화할 수 있습니다.
- 다양한 데이터 타입을 지원합니다. 아래 표 참고
Built-in Operator Classes
| 이름 | 인덱스 타는 연산자 |
|---|---|
| array_ops | && (anyarray,anyarray) |
| @> (anyarray,anyarray) | |
| <@ (anyarray,anyarray) | |
| = (anyarray,anyarray) | |
| jsonb_ops | @> (jsonb,jsonb) |
| @? (jsonb,jsonpath) | |
| @@ (jsonb,jsonpath) | |
| ? (jsonb,text) | |
| ?| (jsonb,text[]) | |
| ?& (jsonb,text[]) | |
| jsonb_path_ops | @> (jsonb,jsonb) |
| @? (jsonb,jsonpath) | |
| @@ (jsonb,jsonpath) | |
| tsvector_ops | @@ (tsvector,tsquery) |
| @@ (tsvector,text) |
jsonb 유형의 경우 jsonb_ops 가 기본값입니다. jsonb_path_ops는 더 적은 연산자를 지원하지만, 더 나은 성능을 제공합니다. (참고)