MySQL 좌표 데이터 가져오기 (+ Spatial Index 활용하기)
목차
좌표 사이의 거리 구하기
제가 사용중인 MySQL 8.0 버전에서 두 좌표의 거리를 계산할 수 있게 해주는
ST_Distance_Sphere 라는 함수를 사용할 수 있습니다
내용은 간단합니다
ST_Distance_Sphere(g1: geometry, g2: geometry)
Point는 geometry형에 속하므로 g1, g2에 Point 자료형을 넣어서 계산해주면 됩니다
실제로 실행해보겠습니다
SET @my_home = Point(127.0569, 37.2876);
SELECT id, name, ST_Distance_Sphere(coordinates, @my_home) as 'distance' FROM locations;
결과는 meter 기준입니다
km로 변환하면 13856.469km가 나오네요

구글맵으로 거리를 계산해봅시다
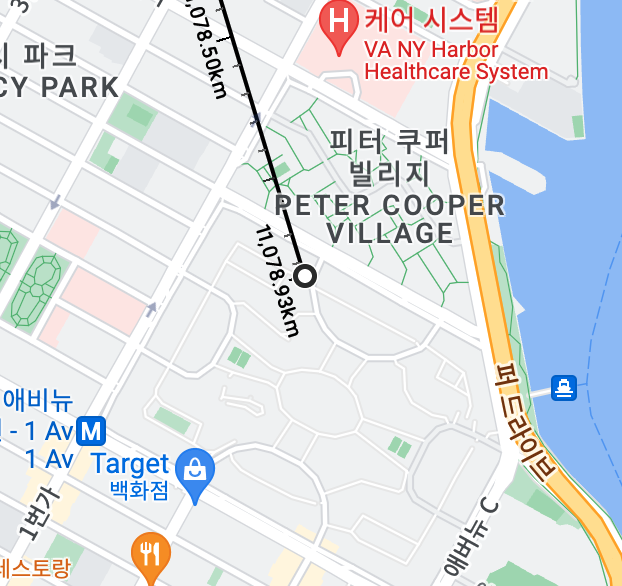
구글맵에선 11078.93km가 나옵니다
1000km가 넘는 오차가 발생하네요
왜 이런 현상이 생기는걸까요?
이건 측정 방식에 대한 오차라고 볼 수 있습니다
ST_Distance_Sphere 함수는 GPS 좌표의 기본값인 WGS 84 기준 타원체를 사용하는데,
Google 지도는 기준 타원체가 다른 측지 데이터를 사용하기 때문에 이런 차이가 생기는 겁니다.
그래도 가까운 거리는 거의 티가 안 날 정도로 비슷한 결과가 나옵니다
서울에 위치한 롯데타워를 데이터에 추가해서 테스트해보겠습니다
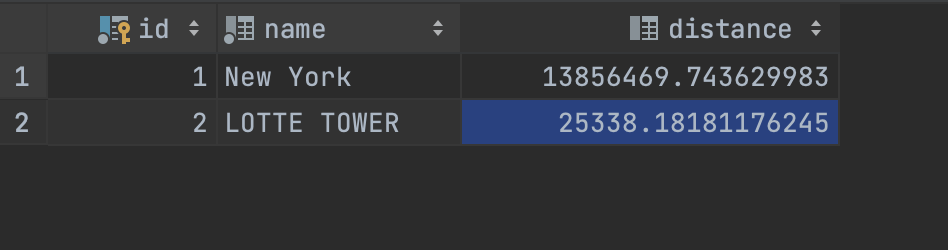
롯데타워로부터 집까지의 거리가 25.338km로 구글맵의 25.32km와 비슷하게 나오네요
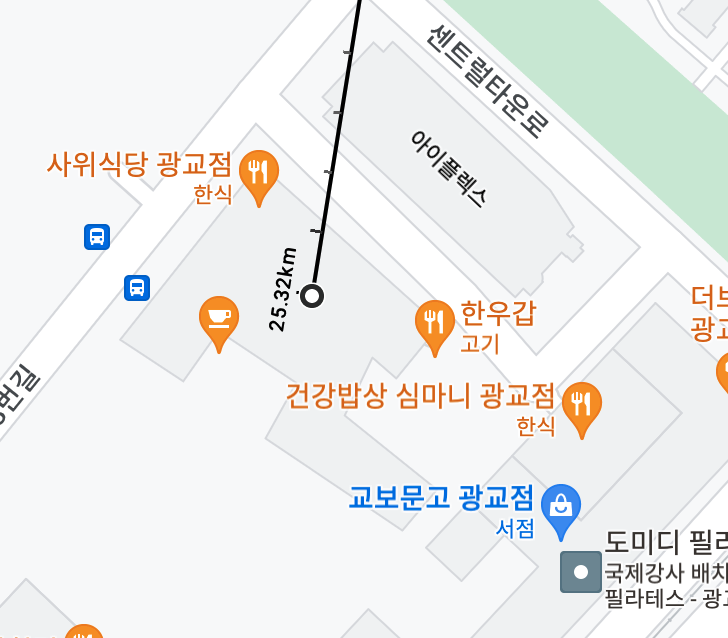
특정 거리 이내 장소 쿼리하기
30km 이내 장소를 쿼리하는 SQL입니다
SELECT id, name, ST_Distance_Sphere(coordinates, @my_home) as 'distance' FROM locations
WHERE ST_Distance_Sphere(coordinates, @my_home) < (30 * 1000);

뉴욕이 안나왔네요 성공!
성능 최적화하기
공간 인덱스 (Spatial index)
point, line, polygon 데이터와 같은 DB에서 공간 쿼리 작업 성능을 향상시키는 데 사용되는 인덱스입니다
공간 인덱스를 사용해서 점의 특정 거리 내에 있는 객체를 찾는 작업 속도를 높일 수 있습니다
공간 인덱스는 셀이라고 하는 더 작고 관리하기 쉬운 청크로 분할해서 작동합니다
각 셀에는 객체 집합이 들어있으며 셀은 MySQL에서 공간 인덱스는 R-Tree 라는 자료구조를 사용하고 2차원 공간의 데이터를 인덱싱하는 데 사용됩니다
(R-Tree는 공간 쿼리에 최적화된 트리 기반 자료구조 입니다)
Spatial Index 추가하기
(저는 SRID에 문제가 있었는지 테스트할 때 제대로 동작하지 않아서 수정해줬습니다)
locations MODIFY coordinates POINT NOT NULL SRID 0;
spatial index를 추가해봅시다
CREATE SPATIAL INDEX geo_index ON locations(coordinates);
특정 거리 이내 데이터 가져오기
spatial index만 추가했는데 과연 성능이 좋아졌을까요?
→ 꼭 그렇진 않습니다
성능 테스트를 위해 약 11000개의 서울시 버스정류장 데이터를 DB에 넣어뒀습니다
그리고 실행 계획을 보겠습니다
EXPLAIN
SELECT id, name, ST_Distance_Sphere(coordinates, @my_company) as 'distance' FROM locations
WHERE ST_Distance_Sphere(coordinates, @my_company) < (2000);

결과는 다음과 같습니다
회사 근처 데이터가 잘 나옵니다
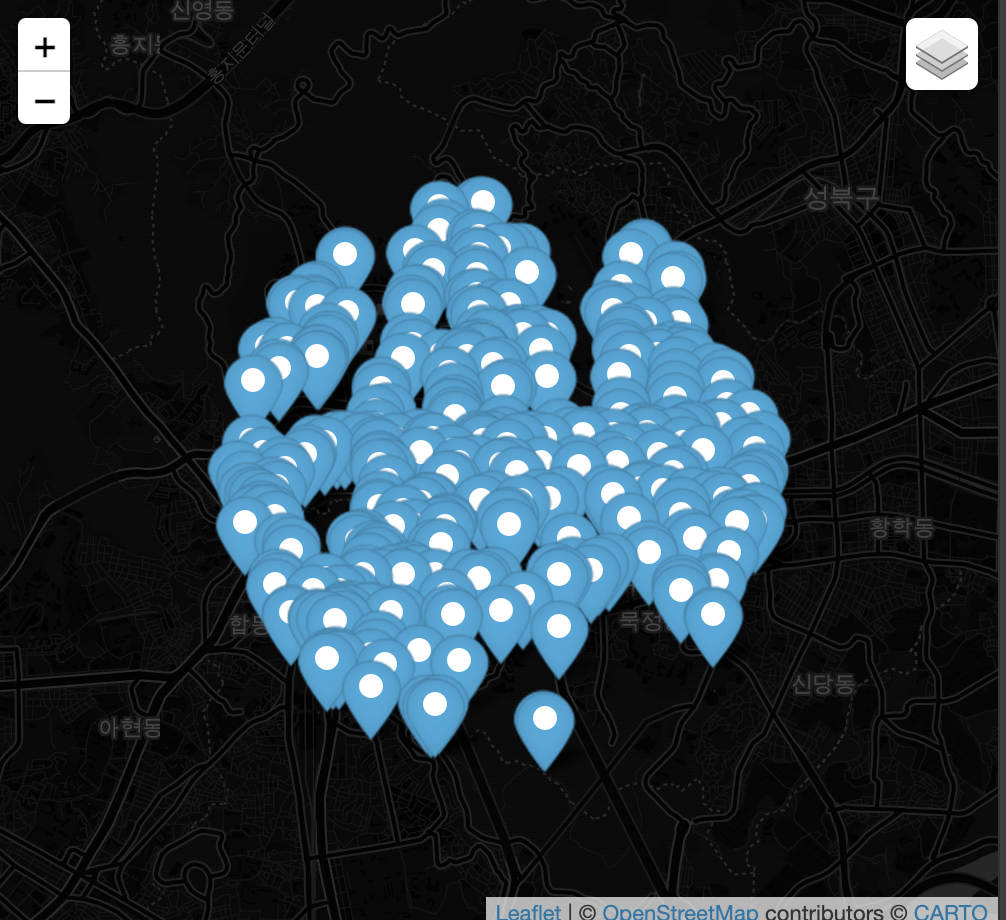
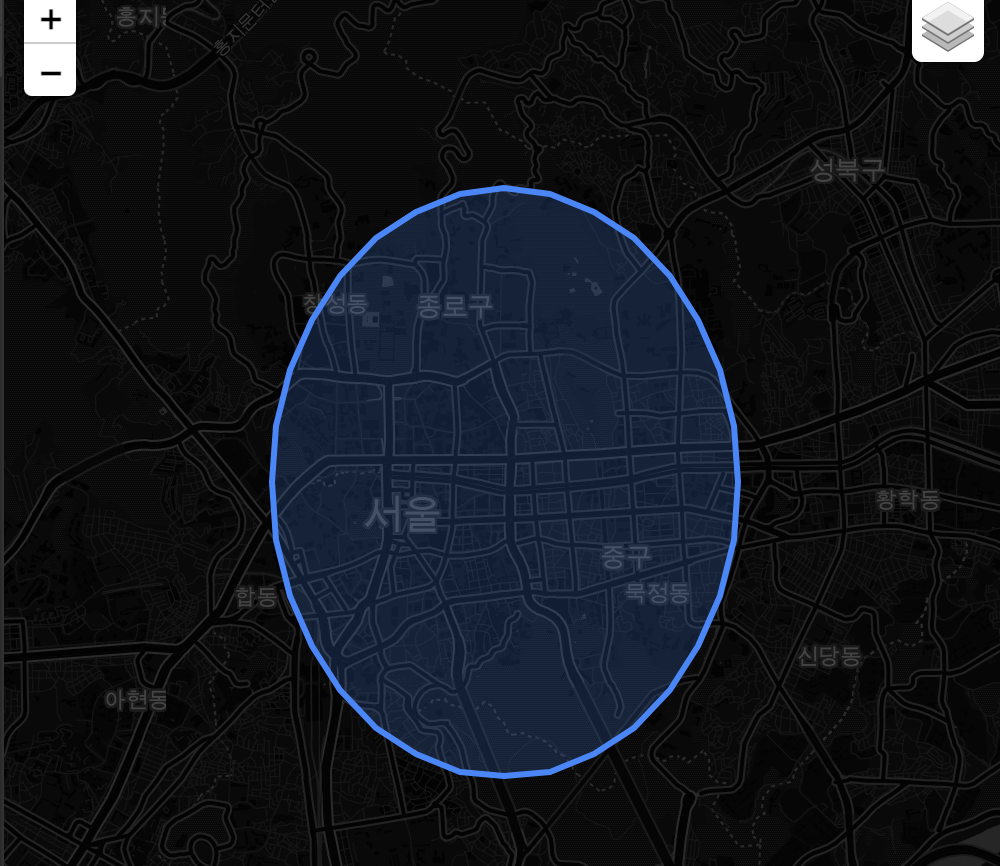
우선 다니고 있는 회사에서 2km 반경의 공간을 미리 세팅했습니다
ST_Buffer(g1 Geometry, d Double) 기능을 사용할 건데요
특정 Geometry 객체에서 d만큼 확장된 Geometry 객체를 반환합니다
SELECT ST_Buffer(@my_company, 0.02);
원이 좀 이상하지만 비슷한 듯 해서 그냥 진행해보겠습니다
그리고 마찬가지로 실행계획을 보겠습니다
EXPLAIN
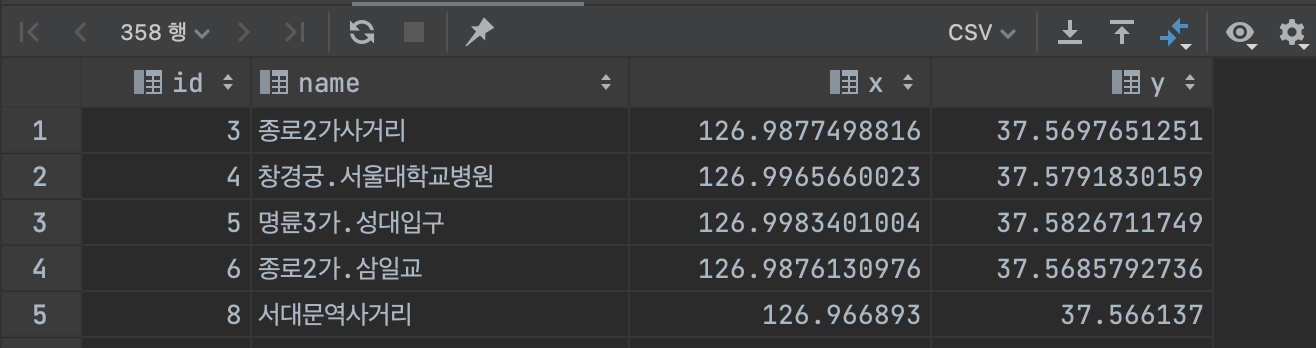
SELECT id, name, ST_X(coordinates) as 'x', ST_Y(coordinates) as 'y'
FROM locations
WHERE ST_Contains(ST_Buffer(@my_company, 0.02), coordinates);
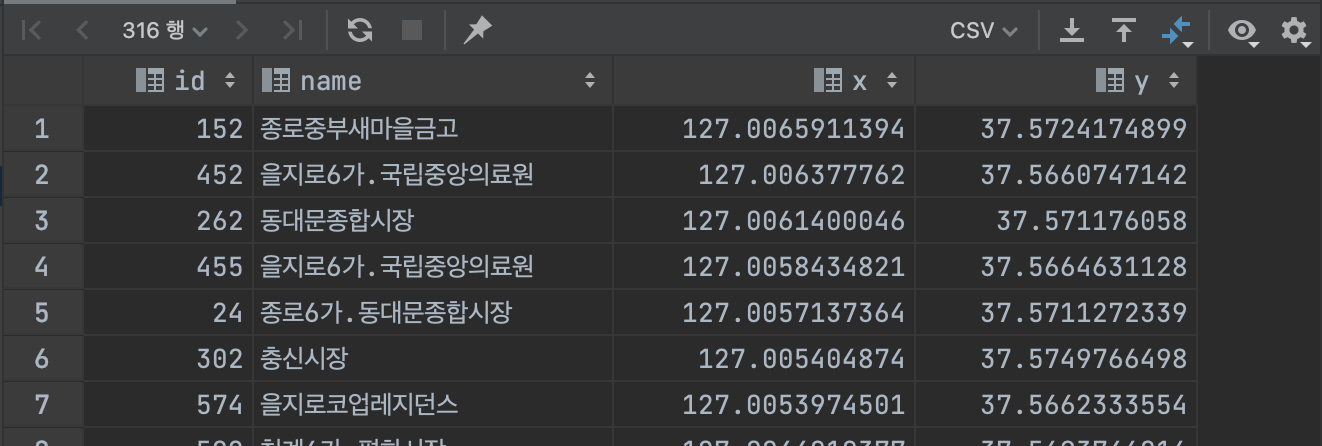
334 rows로 가져올 행의 수가 11000개보단 적습니다

그리고 이제 해당 범위 내의 좌표를 뽑아보면 실제로 회사 근처의 정류장들이 나옵니다
시간은 얼마나 차이가 날까요?
이건 ST_Distance_Sphere 함수로 거리 차이를 비교해서 모든 행을 검사한 경우입니다

이건 spatial indexing이 적용된 경우입니다

만개가 넘는 데이터에서 약 4배 정도로 유의미한 차이를 보여주는 것 같습니다
더 알아볼 내용
- ST_Buffer 두 번째 인자 세팅 어떻게 하는건지
- SRID가 뭔지
실습 깃허브
https://github.com/kwanok/spatial-query-study
Reference
https://youngwoon.tistory.com/3